

Cracking the Code
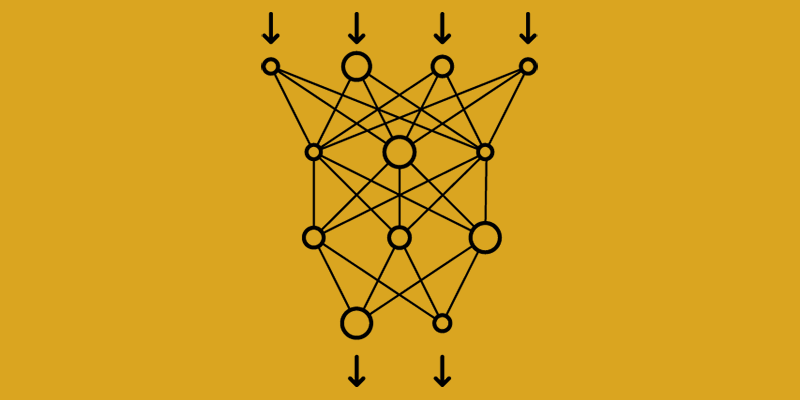
In the discipline of artificial intelligence, neural networks have emerged as a transformative force, propelling advancements across various domains. At the heart of these networks lies the process of backpropagation, an intricate mechanism that fuels learning, optimization, and convergence. In this article, we will discuss backpropagation, its significance, explain its mechanics, and the role it plays in shaping the potency of neural networks.
The Essence of Backpropagation
Backpropagation, short for “backward propagation of errors,” is a cornerstone of neural network training. It is the algorithmic backbone that empowers neural networks to learn from data, fine-tune their weights, and improve their ability to make accurate predictions or classifications.
Imagine training a neural network to recognize handwritten digits. Initially, the network’s weights are random, leading to random outputs. Backpropagation, coupled with an optimization algorithm like gradient descent, adjusts these weights iteratively to minimize the difference between predicted and actual outputs. This iterative adjustment, driven by the gradient of the loss function, refines the network’s ability to make precise predictions.
The Mechanics of Backpropagation
At its core, backpropagation hinges on the principle of error attribution. It computes the gradient of the loss function with respect to each weight in the network. This gradient indicates the direction and magnitude of change needed to minimize the loss function.
The process involves two main phases:
- Forward Pass: During the forward pass, input data traverses through the network’s layers. Each layer computes a weighted sum of inputs, applies an activation function, and passes the transformed output to the next layer. The final output is compared to the actual target values using a loss function, generating an initial error signal
- Backward Pass: In the backward pass, the error signal is propagated backward through the layers. The gradient of the loss function with respect to each weight is calculated using the chain rule of calculus. This gradient indicates how much each weight contributes to the error. By iteratively adjusting the weights in the opposite direction of the gradient, the network gradually minimizes the loss function
The Role of Activation Functions in Backpropagation
Activation functions play a vital role in backpropagation. They determine the shape of the network’s loss surface, affecting how gradients flow during training. Activation functions with well-behaved gradients, like ReLU, facilitate smoother convergence. Those with vanishing gradients, like sigmoid and tanh, can slow down learning or even lead to vanishing gradient issues.
Challenges and Solutions
Backpropagation is not without challenges. The vanishing gradient problem occurs when gradients become extremely small during the backward pass, making weight updates minuscule. This can stall learning, particularly in deep networks. To mitigate this, activation functions like ReLU are often favored due to their propensity to maintain more substantial gradients.
The exploding gradient problem, on the other hand, involves gradients becoming exceedingly large and causing unstable training. Gradient clipping and proper weight initialization strategies help address this issue.
Advancements in Backpropagation
Over the years, various enhancements and optimizations have emerged to refine backpropagation:
- Batch Gradient Descent: Rather than updating weights after each input, batch gradient descent computes gradients for a batch of inputs and updates weights accordingly. This can lead to faster convergence and more stable updates
- Stochastic Gradient Descent (SGD): SGD processes a single training example at a time, introducing randomness into weight updates. This randomness can help escape local minima and converge to better solutions
- Mini-Batch Gradient Descent: A compromise between batch and stochastic gradient descent, mini-batch SGD processes a small subset (mini-batch) of training data at each iteration
The Learning Dynamics
Backpropagation is the linchpin that empowers neural networks to evolve from raw data to intelligent decision-making engines. Its intricate process of iteratively fine-tuning weights, guided by gradients, leads to the network’s ability to comprehend patterns, detect anomalies, and predict outcomes.
As AI continues to evolve, backpropagation remains an integral part of the deep learning journey. It embodies the essence of learning dynamics, unraveling the mysteries of neural network training. Through backpropagation, neural networks harness the power of mathematical optimization to uncover insights, transforming the realm of possibilities across industries and reshaping the future of technology.




